하위 도메인없이 유효한 도메인 이름과 일치하는 정규 표현식은 무엇입니까?
먼저 정규식 10,000 번째 질문에 대해 죄송합니다.
다른 도메인 관련 질문이 있지만 정규식이 제대로 작동하지 않거나 너무 복잡하거나 하위 도메인, 프로토콜 및 파일 경로가있는 URL에 대해 알고 있습니다.
내 것이 더 간단합니다. 도메인 이름을 확인해야합니다.
google.com
stackoverflow.com
따라서 www와 같은 하위 도메인도 아닌 가장 원시적 인 형태의 도메인입니다.
- 문자는 az | AZ | 0-9 및 마침표 (.) 및 대시 (-)
- 도메인 이름 부분은 대시 (-)로 시작하거나 끝나서는 안됩니다 (예 : -google-.com).
- 도메인 이름 부분은 1 ~ 63 자 사이 여야합니다.
-
확장 (TLD)은 현재 # 1 규칙에 따라 무엇이든 될 수 있습니다. 나중에 목록과 비교하여 유효성을 검사 할 수 있지만 1 자 이상이어야합니다.
편집 : TLD는 분명히 2-6 자입니다.
아니. 4 개정 됨 : TLD는 .co.uk와 같은 것을 포함해야하므로 실제로 "하위 도메인"이라는 레이블이 지정되어야합니다. 가능한 유일한 유효성 검사 (목록에 대한 검사는 제외)는 '첫 번째 점 뒤에 하나 또는 규칙 # 1에 따라 더 많은 문자
정말 고마워요, 제가 시도했다고 믿으세요!
음,
특정 요구 사항을 고려할 때 보이는 것보다 약간 더
간단
합니다 (댓글 참조).
/^[a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]\.[a-zA-Z]{2,}$/
그러나 이것은 많은 유효한 도메인을 거부합니다.
나는 이것이 약간 오래된 게시물이라는 것을 알고 있지만 여기의 모든 정규식에는 IDN 도메인 이름에 대한 지원이라는 매우 중요한 구성 요소가 누락되었습니다.
IDN 도메인 이름 은 xn--로 시작합니다. 도메인 이름에 확장 된 UTF-8 문자를 사용할 수 있습니다. 예를 들어 "♡ .com"이 유효한 도메인 이름이라는 것을 알고 계셨습니까? 네, "러브 하트 닷컴"! 도메인 이름을 확인하려면 http://xn--c6h.com/ 이 확인을 통과 하도록해야합니다 .
이 정규식을 사용하려면 도메인을 소문자로 변환하고 IDN 라이브러리를 사용하여 도메인 이름을 ACE로 인코딩해야합니다 ( "ASCII 호환 인코딩"이라고도 함). 좋은 라이브러리 중 하나는 GNU-Libidn입니다.
idn (1)은 국제화 된 도메인 이름 라이브러리에 대한 명령 줄 인터페이스입니다. 다음 예제는 UTF-8의 호스트 이름을 ACE 인코딩으로 변환합니다. 결과 URL https : //nic.xn--flw351e/ 는 https : // nic. 谷 歌 /에 해당하는 ACE 인코딩으로 사용할 수 있습니다 .
$ idn --quiet -a nic.谷歌
nic.xn--flw351e
이 마법의 정규 표현식은 대부분의 도메인을 포함 해야 합니다 (하지만 내가 놓친 유효한 엣지 케이스가 많이 있다고 확신합니다).
^((?!-))(xn--)?[a-z0-9][a-z0-9-_]{0,61}[a-z0-9]{0,1}\.(xn--)?([a-z0-9\-]{1,61}|[a-z0-9-]{1,30}\.[a-z]{2,})$
도메인 유효성 검사 정규식을 선택할 때 도메인이 다음과 일치하는지 확인해야합니다.
- xn--stackoverflow.com
- stackoverflow.xn--com
- stackoverflow.co.uk
이 세 도메인이 통과하지 못하면 정규 표현식이 합법적 인 도메인을 허용하지 않을 수 있습니다!
체크 아웃 오라클의 국제 언어 환경 설명서에서 다국어 도메인 이름 지원 페이지 자세한 내용은.
여기에서 정규식을 사용해보십시오 : http://www.regexr.com/3abjr
ICANN 은 IDN 도메인의 몇 가지 예를 보는 데 사용할 수있는 위임 된 tld 목록을 보관 합니다.
편집하다:
^(((?!-))(xn--|_{1,1})?[a-z0-9-]{0,61}[a-z0-9]{1,1}\.)*(xn--)?([a-z0-9][a-z0-9\-]{0,60}|[a-z0-9-]{1,30}\.[a-z]{2,})$
이 정규식은 호스트 이름 끝에 '-'가있는 도메인이 유효한 것으로 표시되는 것을 중지합니다. 또한 무제한 하위 도메인을 허용합니다.
내 RegEx는 다음입니다.
^[a-zA-Z0-9][a-zA-Z0-9-_]{0,61}[a-zA-Z0-9]{0,1}\.([a-zA-Z]{1,6}|[a-zA-Z0-9-]{1,30}\.[a-zA-Z]{2,3})$
그것은을위한 괜찮아요 i.oh1.me 및 대한 wow.british-library.uk을
UPD
다음은 업데이트 된 규칙입니다.
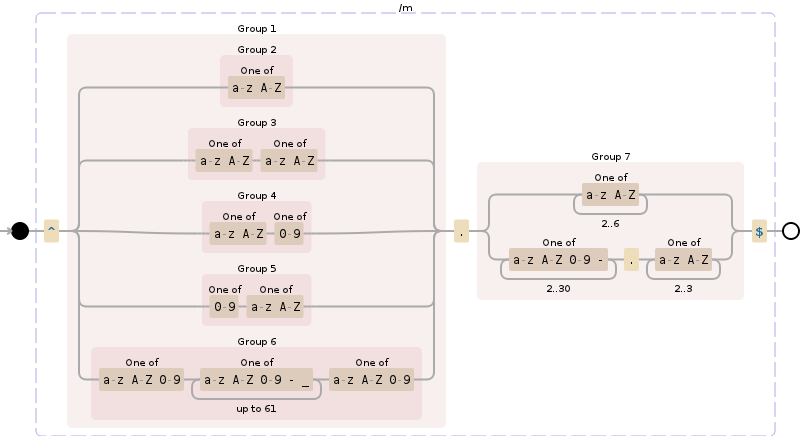
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][a-zA-Z0-9-_]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,6}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
https://www.debuggex.com/r/y4Xe_hDVO11bv1DV
지금은 확인 -하거나 _시작 또는 도메인 라벨의 끝.
내 베팅 :
^(?:[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?\.)+[a-z0-9][a-z0-9-]{0,61}[a-z0-9]$
설명 :
도메인 이름은 세그먼트에서 작성됩니다. 다음은 하나의 세그먼트입니다 (최종 제외).
[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?
1-63 자일 수 있으며 '-'로 시작하거나 끝나지 않습니다.
이제 '.'를 추가하십시오. 그것에 적어도 한 번 반복하십시오 :
(?:[a-z0-9](?:[a-z0-9-]{0,61}[a-z0-9])?\.)+
그런 다음 2 ~ 63 자 길이의 최종 세그먼트를 첨부합니다.
[a-z0-9][a-z0-9-]{0,61}[a-z0-9]
여기에서 테스트하십시오 : http://regexr.com/3au3g
사소한 수정일뿐입니다. 마지막 부분은 최대 6 개 여야합니다. 따라서
^[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,6}$
가장 긴 TLD는 museum(6 자)-http: //en.wikipedia.org/wiki/List_of_Internet_top-level_domains
나를 위해 작동하지 않는 수락 된 대답은 다음을 시도하십시오.
^ ((?!-) [A-Za-z0-9-] {1,63} (? <!-) \.) + [A-Za-z] {2,6} $
검증을 위해이 단위 테스트 사례 를 방문하십시오 .
이 답변은 이메일 호스트 이름과 같은 호스트 이름이 아닌 도메인 이름 (서비스 RR 포함)에 대한 것입니다.
^(?=.{1,253}\.?$)(?:(?!-|[^.]+_)[A-Za-z0-9-_]{1,63}(?<!-)(?:\.|$)){2,}$
It is basically mkyong's answer and additionally:
- Max length of 255 octets including length prefixes and null root.
- Allow trailing '.' for explicit dns root.
- Allow leading '_' for service domain RRs, (bugs: doesn't enforce 15 char max for _ labels, nor does it require at least one domain above service RRs)
- Matches all possible TLDs.
- Doesn't capture subdomain labels.
By Parts
Lookahead, limit max length between ^$ to 253 characters with optional trailing literal '.'
(?=.{1,253}\.?$)
Lookahead, next character is not a '-' and no '_' follows any characters before the next '.'. That is to say, enforce that the first character of a label isn't a '-' and only the first character may be a '_'.
(?!-|[^.]+_)
Between 1 and 63 of the allowed characters per label.
[A-Za-z0-9-_]{1,63}
Lookbehind, previous character not '-'. That is to say, enforce that the last character of a label isn't a '-'.
(?<!-)
Force a '.' at the end of every label except the last, where it is optional.
(?:\.|$)
Mostly combined from above, this requires at least two domain levels, which is not quite correct, but usually a reasonable assumption. Change from {2,} to + if you want to allow TLDs or unqualified relative subdomains through (eg, localhost, myrouter, to.)
(?:(?!-|[^.]+_)[A-Za-z0-9-_]{1,63}(?<!-)(?:\.|$)){2,}
Unit tests for this expression.
Thank you for pointing right direction in domain name validation solutions in other answers. Domain names could be validated in various ways.
If you need to validate IDN domain in it's human readable form, regex \p{L} will help. This allows to match any character in any language.
Note that last part might contain hyphens too! As punycode encoded Chineese names might have unicode characters in tld.
I've came to solution which will match for example:
- google.com
- masełkowski.pl
- maselkowski.pl
- m.maselkowski.pl
- www.masełkowski.pl.com
- xn--masekowski-d0b.pl
- 中国互联网络信息中心.中国
- xn--fiqa61au8b7zsevnm8ak20mc4a87e.xn--fiqs8s
Regex is:
^[0-9\p{L}][0-9\p{L}-\.]{1,61}[0-9\p{L}]\.[0-9\p{L}][\p{L}-]*[0-9\p{L}]+$
NOTE: This regexp is quite permissive, as is current domain names allowed character set.
UPDATE: Even more simplified, as a-aA-Z\p{L} is same as just \p{L}
NOTE2: The only problem is that it will match domains with double dots in it... , like masełk..owski.pl. If anyone know how to fix this please improve.
Not enough rep yet to comment. In response to paka's solution, I found I needed to adjust three items:
- The dash and underscore were moved due to the dash being interpreted as a range (as in "0-9")
- Added a full stop for domain names with many subdomains
- Extended the potential length for the TLDs to 13
Before:
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][a-zA-Z0-9-_]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,6}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
After:
^(([a-zA-Z]{1})|([a-zA-Z]{1}[a-zA-Z]{1})|([a-zA-Z]{1}[0-9]{1})|([0-9]{1}[a-zA-Z]{1})|([a-zA-Z0-9][-_\.a-zA-Z0-9]{1,61}[a-zA-Z0-9]))\.([a-zA-Z]{2,13}|[a-zA-Z0-9-]{2,30}\.[a-zA-Z]{2,3})$
^[a-z0-9]+([\-\.]{1}[a-z0-9]+)*\.[a-z]{2,7}$
[domain - lower case letters and 0-9 only] [can have a hyphen] + [TLD - lower case only, must be beween 2 and 7 letters long]
http://rubular.com/ is brilliant for testing regular expressions!
Edit: Updated TLD maximum to 7 characters for '.rentals' as Dan Caddigan pointed out.
^[a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]\.[a-zA-Z]+(\.[a-zA-Z]+)$
For new gTLDs
/^((?!-)[\p{L}\p{N}-]+(?<!-)\.)+[\p{L}\p{N}]{2,}$/iu
^((localhost)|((?!-)[A-Za-z0-9-]{1,63}(?<!-)\.)+[A-Za-z]{2,253})$
Thank you @mkyong for the basis for my answer. I've modified it to support longer acceptable labels.
Also, "localhost" is technically a valid domain name. I will modify this answer to accommodate internationalized domain names.
Here is complete code with example:
<?php
function is_domain($url)
{
$parse = parse_url($url);
if (isset($parse['host'])) {
$domain = $parse['host'];
} else {
$domain = $url;
}
return preg_match('/^(?!\-)(?:[a-zA-Z\d\-]{0,62}[a-zA-Z\d]\.){1,126}(?!\d+)[a-zA-Z\d]{1,63}$/', $domain);
}
echo is_domain('example.com'); //true
echo is_domain('https://example.com'); //true
echo is_domain('https://.example.com'); //false
echo is_domain('https://localhost'); //false
As already pointed out it's not obvious to tell subdomains in the practical sense. We use this regex to validate domains which occur in the wild. It covers all practical use cases I know of. New ones are welcome. According to our guidelines it avoids non-capturing groups and greedy matching.
^(?!.*?_.*?)(?!(?:[\d\w]+?\.)?\-[\w\d\.\-]*?)(?![\w\d]+?\-\.(?:[\d\w\.\-]+?))(?=[\w\d])(?=[\w\d\.\-]*?\.+[\w\d\.\-]*?)(?![\w\d\.\-]{254})(?!(?:\.?[\w\d\-\.]*?[\w\d\-]{64,}\.)+?)[\w\d\.\-]+?(?<![\w\d\-\.]*?\.[\d]+?)(?<=[\w\d\-]{2,})(?<![\w\d\-]{25})$
Proof and explanation: https://regex101.com/r/FLA9Bv/9
There're two approaches to choose from when validating domains.
By-the-books FQDN matching (theoretical definition, rarely encountered in practice):
- max 253 character long (as per RFC-1035/3.1, RFC-2181/11)
- max 63 character long per label (as per RFC-1035/3.1, RFC-2181/11)
- any characters are allowed (as per RFC-2181/11)
- TLDs cannot be all-numeric (as per RFC-3696/2)
- FQDNs can be written in a complete form, which includes the root zone (the trailing dot)
Practical / conservative FQDN matching (practical definition, expected and supported in practice):
- by-the-books matching with the following exceptions/additions
- valid characters:
[a-zA-Z0-9.-] - labels cannot start or end with hyphens (as per RFC-952 and RFC-1123/2.1)
- TLD 최소 길이는 2 자, 최대 길이는 현재 기존 레코드에 따라 24 자입니다.
- 후행 점과 일치하지 않음
/^((([a-zA-Z]{1,2})|([0-9]{1,2})|([a-zA-Z0-9]{1,2})|([a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9]))\.)+[a-zA-Z]{2,6}$/
([a-zA-Z]{1,2})-> 두 문자 만 허용합니다.([0-9]{1,2})-> 두 개의 숫자 만 허용
2를 초과하는 것이 있으면 ([a-zA-Z0-9][a-zA-Z0-9-]{1,61}[a-zA-Z0-9])이 정규식이 처리합니다.
매칭을 원할 경우 적어도 한 번 +사용됩니다.
^ [a-zA-Z0-9] [-a-zA-Z0-9] + [a-zA-Z0-9]. [az] {2,3} (. [az] {2,3}) ? (. [az] {2,3})? $
작동하는 예 :
stack.com
sta-ck.com
sta---ck.com
9sta--ck.com
sta--ck9.com
stack99.com
99stack.com
sta99ck.com
확장 기능에서도 작동합니다.
.com.uk
.co.in
.uk.edu.in
작동하지 않는 예 :
-stack.com
가장 긴 도메인 확장자로도 작동합니다. ".versicherung"
'programing tip' 카테고리의 다른 글
| C 함수 내부의 정적 변수 (0) | 2020.08.16 |
|---|---|
| Java에 Null OutputStream이 있습니까? (0) | 2020.08.16 |
| ASP.NET MVC 성능 (0) | 2020.08.16 |
| Android Studio에서 프로젝트 제거 (0) | 2020.08.16 |
| 이미 존재하는 문자열에 어떻게 추가합니까? (0) | 2020.08.16 |